
В самом языке C/C++, в отличие от современных высокоуровневых языков программирования, нет отдельного удобного инструмента для работы с текстом (строками). Да, есть библиотеки, но мы сейчас рассматриваем сам язык. На уровне синтаксиса строка - это массив символов, то есть значений типа char.
Символы #
Для хранения текстовых символов в памяти компьютера была придумана таблица ASCII - стандартная таблица символов. В неё входят латинские буквы (большие и маленькие, a-z A-Z), арабские цифры 0-9, символы, которые можно увидеть на клавиатуре компьютера, а также ряд непечатных символов. Каждому символу в таблице соответствует численный код от 0 до 127 - всего 128 символов.
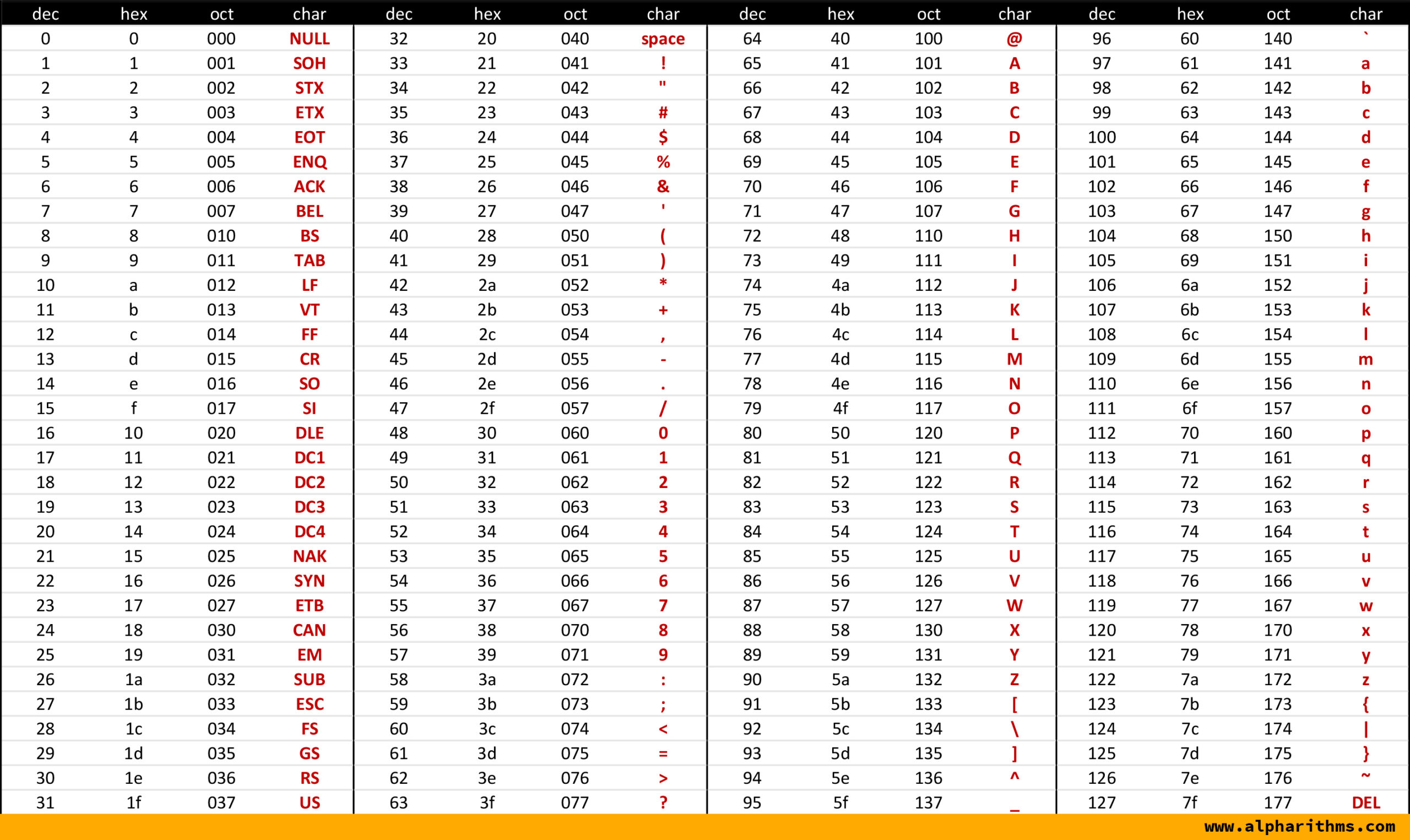
Таблица ASCII
Тип char #
Тип char - character (символ), занимает 1 байт и хранит в себе целое число - код символа в ASCII, т.е. программа ничего не знает про символы - для неё это просто числа. В C/C++ есть специальный синтаксис для символов - его нужно заключить в одинарные кавычки ':
char sym = 'a'; // число 97 в DEC по таблице
'0' == 48; // trueВ одиночных кавычках без префиксов (о них ниже) может находиться только символ из таблицы ASCII, т.е. цифра, стандартный символ или латинская буква. Если поместить в кавычки например кириллическую букву или смайлик - 'ы', '😁' - они не будут корректно работать, т.к. эти символы занимают несколько байт и работать с ними нужно по другому, а в данном случае они просто обрежутся до одного байта
Символ - это число #
Символы можно сравнивать как числа, например для определения принадлежности к группе символов по таблице ASCII:
char s = '3';
if (s >= '0' && s <= '9'); // если символ - цифра
if (s >= 'A' && s <= 'Z'); // если символ - большая букваТакже с ними можно производить математические операции вперемешку с числами:
char s = 'A' + 2; // == 'C'
++s; // == 'D'Для перевода десятичной цифры-символа (его кода ASCII) в обычную цифру или обратно достаточно вычесть или прибавить значение символа '0', чтобы получить нужный код в таблице:
'5' - '0' == 55 + '0' == '5'
Экранирование #
Одинарная кавычка ' - тоже символ, как записать её в программе? Для этого используется экранирование (escape) при помощи обратного слэша. А как в таком случае записать сам слэш? Экранировать его точно так же:
char quote = '\'';
char bslash = '\\';
char space = ' '; // пробел
//char kek = 'kek'; // ошибка, может быть только один символНепечатные символы #
Таблица начинается с непечатных системных символов, номера 0.. 31. Большинство из них были нужны для управления принтерами, поэтому они так и называются - управляющие символы (control characters), но некоторые используются и в обычном тексте. Например
'\t'- символ горизонтальной табуляции, клавиша Tab на клавиатуре'\r'- CR, Carriage Return (возврат каретки), возврат курсора в начало строки'\n'- LF, Line Feed (новая строка), перенос строки вниз
Для совместимости между операционными системами перенос строки выполняется при помощи обоих символов - \r + \n
Под номером 0 в таблице идёт нулевой символ NULL. Его тоже можно записать из программы - по сути это число 0, либо символ '\0':
char n = 0; // NULL
n = '\0'; // NULL
n = NULL; // NULLСтроки #
Строка в Си - это массив символов, то есть переменных типа char или других разновидностей:
char str[10] = {'H', 'e', 'l', 'l', 'o'}; // HelloМассив может иметь размер больше, чем в него записано символов. Как определить, на каком элементе кончается текст? Для этого договорились заканчивать строки нулевым символом '\0' (или просто десятичное число 0), откуда строки в Си получили называние null terminated strings - строки, завершённые нулём. Исправим предыдущий пример:
char str[10] = {'H', 'e', 'l', 'l', 'o', 0}; // Hello - корректная Си-строкаТаким образом корректная строка занимает на 1 байт больше, чем длина печатного текста в ней
Локальный массив char[] для работы со строковыми функциями нужно обязательно инициализировать, если он пустой - {} или "", потому что некоторые функции ищут конец строки
Строковые литералы #
Для большего удобства работы со строками существуют "строковые литералы" - текст в программе, ограниченный двойными кавычками. Строковый литерал имеет тип данных const char[размер] и сразу включает в себя нулевой символ, то есть размер его как массива равен длине текста + 1.
Допустимо обращаться к литералу как к массиву для чтения:
char c = "Hello"[2]; // c == lМассивы символов могут инициализироваться строковыми литералами, в этом случае получается копия литерала в оперативной памяти:
char str[] = "Hello"; // размер 5+1 байт
// str - это массив, мы его создали и можем изменять
str[0] = 'J'; // str == "Jello"Сам строковый литерал - const, изменять его нельзя: в зависимости от архитектуры он может храниться как в оперативной памяти, так и в постоянной:
const char* cstr = "Hello"; // cstr - указатель на саму строку, данные литерала
cstr[0] = 'A'; // ошибка, изменение константы
char* str = (char*)"Hello"; // компилятор может ругаться, но доверится нам
str[0] = 'J'; // скорее всего сломает программу!Стандарт языка предписывает некоторые особенности строковых литералов, которые должны соблюдаться на всех платформах и архитектурах:
- "Массив символов" строкового литерала должен храниться в статической памяти, то есть существовать на протяжении всей работы программы независимо от места своего нахождения и иметь фиксированный адрес, по сути как глобальная переменная. По этому адресу он доступен из всей программы:
const char* getStr1() {
// это не локальный, а статический "массив"!
const char* str = "hello";
// его адрес можно спокойно использовать во всей программе
return str;
}
const char* getStr2() {
return "hello";
}
const char* str1 = getStr1();
const char* str2 = getStr2();Обратный пример:
const char* getStr() {
// это локальный массив char
char str[] = "hello";
// мы вернём указатель на него, но данные удалятся из памяти!
return str;
} // тут массив удалится из памяти
// неопределённое поведение программы
char* str = getStr();- Строковые литералы с одинаковым текстом приводятся к одному адресу в памяти для оптимизации свободного места - string interning, т.е. 10 одинаковых строк займут место как 1 строка:
const char* str1 = "hello";
const char* str2 = "hello";
// str1 == str2, одинаковый адрес, т.к. строки не дублируются в памятиДлина строки #
Мы знаем, что строка всегда оканчивается нулевым символом, который не попадает в читаемую "длину" строки. Поэтому, даже если строка занимает весь массив, оператор sizeof выдаст некорректный результат:
// hello - длина 5
char str1[] = "hello";
char str2[10] = "hello";
sizeof(str1); // 6
sizeof(str2); // 10Длину строки нужно "вычислить" - пройтись по всей строке в поисках нулевого символа, запоминая индекс. Или вот так:
char str[] = "hello";
char* p = str;
while (*p) ++p;
int len = p - str; // len == 5Для работы со строками есть стандартная библиотека string.h (см. справочник), она включает в себя множество инструментов для работы с нуль-терминированными строками. Например - измерение длины, strlen:
strlen("hello"); // 5
char str[] = "hello";
sizeof(str); // 6
strlen(str); // 5
str[2] = 0; // завершим строку на втором символе
// str == {'h', 'e', 0', 'l', 'o', 0}
strlen(str); // 2Безопасность #
Нуль-терминированные строки и "массивы" в Си очень сильно критикуются разработчиками, так как на уровне самого языка никак не проверяется переполнение массива и корректность длины строки. Очень легко можно записать данные за границы массива, если не проверить размер, а также получить некорректые данные, если у строки "потеряется" завершающий ноль. Банально та же функция strlen будет читать память до тех пор, пока не встретит ноль, и может даже выйти за границы памяти... Поэтому работа со строками средствами языка очень непростая, приходится писать множество дополнительных проверок и защит, чтобы избежать дыр в безопасности. Взлом программы через переполнение массива при работе со строками - очень частая практика у хакеров, позволяющая поместить в оперативную память программы какой-то свой код.
В современных языках таких проблем нет, там строка - это отдельный тип данных, который по другому устроен и работает безопасно. В стандартной библиотеке C++ тоже есть удобные высокоуровневые инструменты для строк, где вся безопасность обеспечивается автоматически - std::string. Работать со строками напрямую при помощи инструментов из библиотеки Си - плохая практика, а если не хочется или нет возможности использовать std::string - всегда можно написать свой "инструмент".
Склеивание строк #
Строковые литералы, расположенные друг за другом, склеиваются компилятором в одну строку. Пробелы и переносы между строками не влияют на строку:
const char* str1 = "hello " "world"; // "hello world"
const char* str2 =
"hello "
"world"; // "hello world"Перенос строк #
Строку можно переносить, как код, отделяя переносы обратным слэшем. Эти переносы будут присутствовать только в программе, результирующая строка их не содержит:
const char* str = "Hello\
, \
World!"; // "Hello, World!"Для переноса внутри самого текста используется символ '\n', но для полной совместимости со всеми платформами лучше использовать последовательность \r\n:
const char* str = "line 1\r\nline 2\r\nline 3";
/* при печати получится
line 1
line 2
line 3
*/Экранирование #
Для того, чтобы вставить в строку двойные кавычки или обратный слэш как текст - точно так же экранируем:
const char* str = "hello \" world \\ text"; // hello " world \ textДопустим, нужно создать строку в формате JSON следующего вида: {"str":"text","value":123}:
const char* json = "{\"str\":\"text\",\"value\":123}";"Слегка" упала читаемость!
Raw строки #
Для большего удобства набора текста, содержащего экранируемые символы, существуют "сырые" строки - raw string literals. Синтаксис такой: R"(текст)" или R"ключ(текст)ключ". Здесь ключ - произвольный набор символов (буквы, цифры, подчёркивание, длина до 16), нужен в том случае, когда сама строка содержит круглые скобки - чтобы компилятор мог корректно найти конец сырой строки. Например строка с содержимым )" - R"()")" - будет ошибка. Добавим ключ: R"raw()")raw" - теперь всё правильно.
Перепишем прошлый пример с JSON:
const char* json = R"({"str":"text","value":123})"; // == {"str":"text","value":123}Стало гораздо лучше! В сырых строках переносы в коде программы являются переносами в тексте строки, то есть для создания многострочного текста символы переноса писать не нужно:
const char* str = R"(line 1
line 2
line 3)";
/* при печати получится
line 1
line 2
line 3
*/R"()"строки крайне удобны при работе с JSON или XML/HTML разметкой и в других форматах, где много двойных кавычек
Массив строк #
Так как строковые литералы - это массивы, можно сделать на них массив указателей const char*:
const char* strs[] = {
"Text",
"Hello world",
"Line 3",
};
strs[1]; // имеет тип const char*
strlen(strs[1]); // 11Это - массив строковых литералов, то есть изменять их нельзя - только для чтения
Можно сделать массив массивов в оперативной памяти, то есть доступную для изменения сущность. Вспоминаем логику работы двухмерных массивов: нужно обязательно указать размерность самих массивов элементов, по сути - установить максимальную длину строки в рамках всего двухмерного массива:
// с запасом 15 символов
char strs[][15] = {
"Text",
"Hello world",
"Line 3",
};
strs[0][0] = 'K'; // "Kext"Такая конструкция потребляет лишнюю память (если строки разной длины), пока существует в памяти.
Работа со строками #
Работа со строками обычно заключается в сборке строки с определённым текстом, либо поиске в строке нужных подстрок и символов. В Си есть стандартная библиотека string.h с функциями для работы со строками, она разобрана в справочнике. Работать с ней не рекомендуется - это неудобно и небезопасно. Используйте более высокоуровневые инструменты, такие как String (Arduino) или std::string (C++ std).
Другие кодировки #
Универсальный код символов (UCN) #
Есть несколько форматов записи символов, далее N - число:
| Формат | Тип | Пример |
|---|---|---|
| Нет | Просто печатный символ | 'A' (символ А) |
\NN.. |
Код в 8-ричной системе | '\101' (символ А) |
\xNN.. |
Код в 16-ричной системе | '\x41' (символ А) |
\uNNNN |
UCN 16 (2 байта) | '\u0041' (символ А) |
\UNNNNNNNN |
UCN 32 (4 байта) | '\U00000041' (символ А) |
Таким образом, символы могут быть не только 1 байтные, но и 2/4 байтные.
Кириллица и другие алфавиты #
Кириллица (русские буквы) и многие другие языки имеют свой набор символов, который не описывается таблицей символов ASCII - там только латинский алфавит. Поэтому существует более "общая" таблица символов (кодировка) - unicode, которая содержит как все языки мира, так и всякие символы, смайлики и эмодзи. Юникод 32 битный, то есть теоретически поддерживает ~4.3 миллиарда символов - хватит всем!
Кириллица, смайлики и прочие нестандартные символы кодируются несколькими байтами
Символы юникода, вставленные в строковый литерал в явном виде или в UCN, автоматически поделятся на байты компилятором и строка будет иметь уже совсем другую длину:
const char* str = "ё";
strlen(str); // 2 символа
strlen("\u0451"); // 2 символа, это та же буква ё
strlen("😉"); // 4 символа
strlen("\U0001F609"); // 4 символа, это тот же смайлик 😉При выводе такого текста на печать он будет напечатан корректно, если печатающая программа поддерживает юникод.
Большие символы #
Для хранения символов размером больше одного байта есть специальные типы данных:
| Тип | Размер, Б | Префикс | Пример |
|---|---|---|---|
char |
1 | Нет | "text", 'A' |
wchar_t |
2 | L |
L"text", L'\u0451' |
char16_t |
2 | u |
u"text", u'\u0451' |
char32_t |
4 | U |
U"text", U'\U0001F609' |
И всё это работает по такой же логике:
const char* s1 = "😉 == \U0001F609";
const wchar_t* s2 = L"😉 == \U0001F609";
const char16_t* s3 = u"😃 == \U0001F603";
const char32_t* s4 = U"😎 == \U0001F60E";
// один и тот же смайлик в разной записи
wchar_t c1 = L'😉';
wchar_t c2 = L'\U0001F609';
wchar_t c3 = L'\x1f609';Выводить данные на печать в таком формате уже не получится, но может понадобиться для других целей.
Дополнительно #
Дополнительный контент доступен владельцам набора GyverKIT и по подписке, подробнее читай здесь. Блок содержит:
- Тезисы, Задания, Примеры (Arduino)
- 12 блоков кода
Полезные страницы #
- Набор GyverKIT – наш большой стартовый набор Arduino, продаётся в России
- Каталог ссылок на дешёвые Ардуины, датчики, модули и прочие железки с AliExpress
- Обратная связь – сообщить об ошибке в уроке или предложить дополнение по тексту (alex@alexgyver.ru)
- Поддержать автора за работу над уроками