
Сравнение строк #
Строка - это массив символов. Строки сравниваются посимвольно от начала до конца, с проверкой на наличие нулевого символа (конца строки). Так работает стандартная функция strcmp, а также Ардуиновская String-строка, которая умеет нативно сравниваться с другими строками:
// C
char cstr[] = "kek";
strcmp(cstr, "kek");
// Arduino
String str;
str == cstr;
str == "abc";
str == F("def");Выбор строк #
Допустим, у нас есть некоторый текстовый протокол связи - как для Serial из урока про Serial или мы пишем чат-бота, например обработку callback query нажатий кнопок у Телеграм бота. И там и там возникает ситуация, когда программа должна отреагировать на полученный текст в соответствии с его "значением", то есть существует набор значений строк, по которым программа должна "разветвиться". Самый очевидный способ сделать это - сравнивать полученную строку с набором известных текстов. Например так:
int v = -1;
if (!strcmp(str, "abcdef0")) v = 0;
else if (!strcmp(str, "abcdef1")) v = 1;
else if (!strcmp(str, "abcdef2")) v = 2;
else if (!strcmp(str, "abcdef3")) v = 3;
else if (!strcmp(str, "abcdef4")) v = 4;
else if (!strcmp(str, "abcdef5")) v = 5;
else if (!strcmp(str, "abcdef6")) v = 6;
else if (!strcmp(str, "abcdef7")) v = 7;Это будет работать следующим образом: программа будет сравнивать полученную строку по очереди со всеми известными строками, пока не получит совпадение или строки не закончатся. Чем длиннее этот список и чем больше строк с одинаковым началом - тем потенциально медленнее будет работать программа, а чем дальше искомая строка находится в списке - тем фактически дольше выполняется вся конструкция.
Здесь я присваиваю v просто для "отладки" и как пример того, что от разных строк будет выполняться разный код
В реальной программе мы скорее всего получим строку в формате String, а её можно сравнить через оператор ==:
if (str == "abcdef0") v = 0;
else if (str == "abcdef1") v = 1;
else if (str == "abcdef2") v = 2;
else if (str == "abcdef3") v = 3;
else if (str == "abcdef4") v = 4;
else if (str == "abcdef5") v = 5;
else if (str == "abcdef6") v = 6;
else if (str == "abcdef7") v = 7;Если вариантов много, то возможно мы захотим сэкономить оперативную память и закинем строки в PROGMEM, например через F-макрос:
if (str == F("abcdef0")) v = 0;
else if (str == F("abcdef1")) v = 1;
else if (str == F("abcdef2")) v = 2;
else if (str == F("abcdef3")) v = 3;
else if (str == F("abcdef4")) v = 4;
else if (str == F("abcdef5")) v = 5;
else if (str == F("abcdef6")) v = 6;
else if (str == F("abcdef7")) v = 7;Ситуация усугубится - сравнение String строки с F-строкой происходит в несколько этапов:
- Создание новой временной
String-строки - Измерение длины строки в PGM
- Выделение динамического буфера под этот размер
- Копирование строки из PGM в буфер
- Сравнение строк через
strcmp
Как результат - программа станет работать ещё медленнее. Результаты тестов (AVR 16 MHz, микросекунды):
strcmp(str, "str") |
str == "str" |
str == F("str") |
|
|---|---|---|---|
| Первое совпадение | 5 | 7 | 41 |
| Последнее совпадение | 38 | 52 | 327 |
Для оптимизации подобных конструкций существуют хэш-строки (hash string).
Хэш #
Хэш (hash) - это целое число или массив фиксированного размера (по сути тоже число, только очень большое, которое не умещается в стандартный 32 или 64 бит тип), которое является уникальным отпечатком данных, полученным в результате работы хэш-функции. В свою очередь хэш-функция принимает данные любого типа и размера и считает их хэш так, что у разных данных получится разный хэш, даже если они отличаются на 1 бит.
Если применить хэш-функцию к строке, то получится значение, которое является уникальным для этой строки, т.е. для этого набора символов. У разных строк будут разные хэши и вместо сравнения строк можно будет сравнивать их хэши, что в программе будет работать многократно быстрее!
Хэш функция #
CRC и контрольная сумма из прошлого урока тоже по сути являются хэш-функциями - выдают разный результат для разных данных. Вообще существует огромное количество алгоритмов хэширования данных и они очень широко применяются на практике в самых разных сценариях, от шифрования до организации баз данных.
В нашем случае нужна какая-нибудь простая хэш-функция, которая выполнялась бы достаточно быстро, чтобы конкурировать со сравнением строк в else-if на микроконтроллере. На самом деле, для получения вполне рабочего хэша короткой строки достаточно просто прибавлять к хэшу значение каждого следующего символа плюс сам хэш, умноженный на некоторое число. Экспериментально было получено число 33 (например оно используется в алгоритмах djb2 и sdbm) - умножение на него отлично оптимизируется в сдвиг и даёт очень хорошее распределение хэша на строках с латинскими буквами - а именно так обычно и выглядят текстовые команды. Стартовое число 5381 здесь получено эмпирически и даёт меньше коллизий. Вот пример реализации:
uint32_t hash(const char* str) {
uint32_t hash = 5381;
while (*str) hash = hash + (hash << 5) + *str++;
return hash;
}Я тестировал данную хэш-функцию на базе из 234'450 английских слов и получил всего 7 коллизий, т.е. у 7 пар слов был одинаковый хэш. Справедливости ради, там были в том числе очень длинные слова, а чем длиннее строка - тем выше вероятность коллизии хэша с другой строкой. На коротких строках коллизии исключены чисто математически.
Теперь мы можем вычислить хэш для любой строки:
hash("hello"); // == 127086708
hash("abc"); // == 108966constexpr #
Настало время подключить к этому делу constexpr-функции. Если хэш "полученной" строки нам придётся посчитать в рантайме, то хэш строк-констант может посчитать компилятор при помощи constexpr-хэш-функции. Благо сама хэш-функция у нас очень простая и может быть переписана под соответствие constexpr даже на уровне C++11 - цикл заменим рекурсией, а локальную переменную перенесём в параметр:
static constexpr uint32_t SH(char const* str, uint32_t hash = 5381) {
return *str ? SH(str + 1, hash + (hash << 5) + *str) : hash;
}В работоспособности конструкции убедиться очень просто:
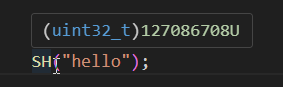
То есть хэш считается компилятором и сама строка вообще не существует в программе - вместо неё подставляется её хэш, число. Этот результат теперь можно использовать как case для switch, т.е. нам приходит строка, мы считаем её хэш и свитчим среди известных вариантов, хэш которых посчитал компилятор:
// или hash(str.c_str()) если это String
switch (hash(str)) {
case SH("abcdef0"): v = 0; break;
case SH("abcdef1"): v = 1; break;
case SH("abcdef2"): v = 2; break;
case SH("abcdef3"): v = 3; break;
case SH("abcdef4"): v = 4; break;
case SH("abcdef5"): v = 5; break;
case SH("abcdef6"): v = 6; break;
case SH("abcdef7"): v = 7; break;
default: break;
}Плюсы такого подхода:
- На разбор результата тратится конечное фиксированное время - время работы хэш-функции. В данном случае это 27 микросекунд на весь код (для 7 символов в строке)
switchвыполняется очень быстро и одинаково для любого количества строк и их содержимого, в отличии отelse if- хоть 10 вариантов, хоть 100, неважно- Если нет совпадений - попадаем в
default:с той же скоростью. В случае сelse ifэто будет самая долгая проверка switchавтоматически даёт защиту от коллизий - программа не скомпилируется, если у двух строк будет одинаковый хэш- Также автоматически получается защита от повторной проверки слова
- Хэши занимают в памяти программы меньше места, чем строки
Библиотеки #
Показанная выше хэш-функция входит в мою библиотеку StringUtils и может быть вызвана как:
// для "строк" (compile time)
SH("hello"); // функция SH
"hello"_h; // литерал _h
H(hello); // макрос H, который превращает слово в строку
// для переменных (runtime)
su::hash(str);Полезные страницы #
- Набор GyverKIT – наш большой стартовый набор Arduino, продаётся в России
- Каталог ссылок на дешёвые Ардуины, датчики, модули и прочие железки с AliExpress
- Обратная связь – сообщить об ошибке в уроке или предложить дополнение по тексту ([email protected])
- Поддержать автора за работу над уроками
